Why you need an iPaaS to build a RAG application
 Updated Feb 13, 2026
Updated Feb 13, 2026

Artificial intelligence (AI) is the science of creating machines capable of performing tasks that usually require human intelligence, such as understanding speech, recognizing images, and making decisions. AI used to be a concept mostly found in science fiction, but as technology has progressed, what once seemed like a far-off dream is now a reality.
For instance, consider the latest advancements in voice conversation and multimodal AI. Today’s AI systems can seamlessly understand and respond to spoken language while simultaneously interpreting visual information, such as identifying objects in images during a conversation.
At the core of these AI advancements is machine learning (ML). ML is a part of AI that teaches computers to learn from data. Instead of programming a computer with specific instructions, we feed it large amounts of data, and it learns to make decisions based on patterns in that data.
For example, imagine teaching a computer to recognize different types of fruit. By showing it thousands of images labeled as apples, oranges, and bananas, it learns to identify each fruit independently.
Now, ML is a huge topic, and we won’t be able to cover all of it in this article. But fear not! We will focus on the current exciting and headline-grabbing part of it: Large Language Models (LLMs).
Let’s dive into this fascinating world where AI can chat, write, and sometimes even joke back!
Overview of large language models
Large language models (LLMs) represent a significant leap in AI capabilities. They are designed to understand and generate human-like text based on patterns they’ve learned from vast amounts of data. These models work like sophisticated auto-completion tools, predicting and generating text that makes sense in context. Trained on massive datasets, LLMs can grasp the nuances of language, allowing them to respond coherently and contextually.
For example, given the prompt “Celigo is an…” an LLM will complete it with “Integration Platform as a Service (iPaaS)” because it has learned this association from its extensive training data.
The era of LLMs has revolutionized how we interact with technology, making AI more accessible and useful in various applications, from chatbots to content creation. But while LLMs are fantastic and trained on trillions of knowledge points, they’re ultimately available publicly.
So what about our private data? How do we get these chatty wonders to help with the sensitive stuff we don’t want to share with the world?
Spoiler alert: LLMs have some pretty well-known limitations, and we’ll dive into those next!
Limitations of LLMs
Despite their impressive capabilities, LLMs have limitations. One major issue is their lack of access to proprietary or specific documents, such as those within a company. This means they can only provide answers based on such documents if explicitly given access.
For instance, if you need insights from your internal reports or confidential files, LLMs can’t help because they haven’t been trained on that specific data.
So, while LLMs are like super-smart parrots, good at general knowledge, they sometimes lack private, specific, or highly detailed information.
Introducing retrieval-augmented generation (RAG), designed to fill those gaps and provide solutions!
RAG: Retrieval-augmented generation
What is RAG?
Retrieval-augmented generation (RAG) is a technique that enhances LLMs by providing them with relevant context from specific sources, allowing them to generate more accurate and context-specific responses. It’s like giving your super-smart parrot a library card to access the necessary information.
How does RAG solve LLM problems?
The magic of RAG starts with providing context to LLMs. By retrieving relevant documents or data and supplying this to the LLM, we can significantly improve the accuracy of its responses. However, it’s crucial to be selective about what context we provide. Just dumping a pile of data won’t do; we need to give the LLM the most relevant information to answer the specific query at hand.
This selective context provision helps hone the response to be precise and reliable.
Reduces hallucinations: If you ask an LLM about a specific company policy, RAG can pull the exact policy document, giving the LLM the precise information it needs to provide a correct answer. This approach not only reduces the risk of hallucinations (where the LLM might otherwise generate plausible but incorrect information) but also ensures that the response is grounded in verifiable data.
Ensures provenance: By carefully selecting and providing the right context, RAG also helps in tracking the source of the information. When an LLM responds based on specific documents you’ve provided, it can point back to those documents, making it easier to verify the answer’s accuracy and origin.
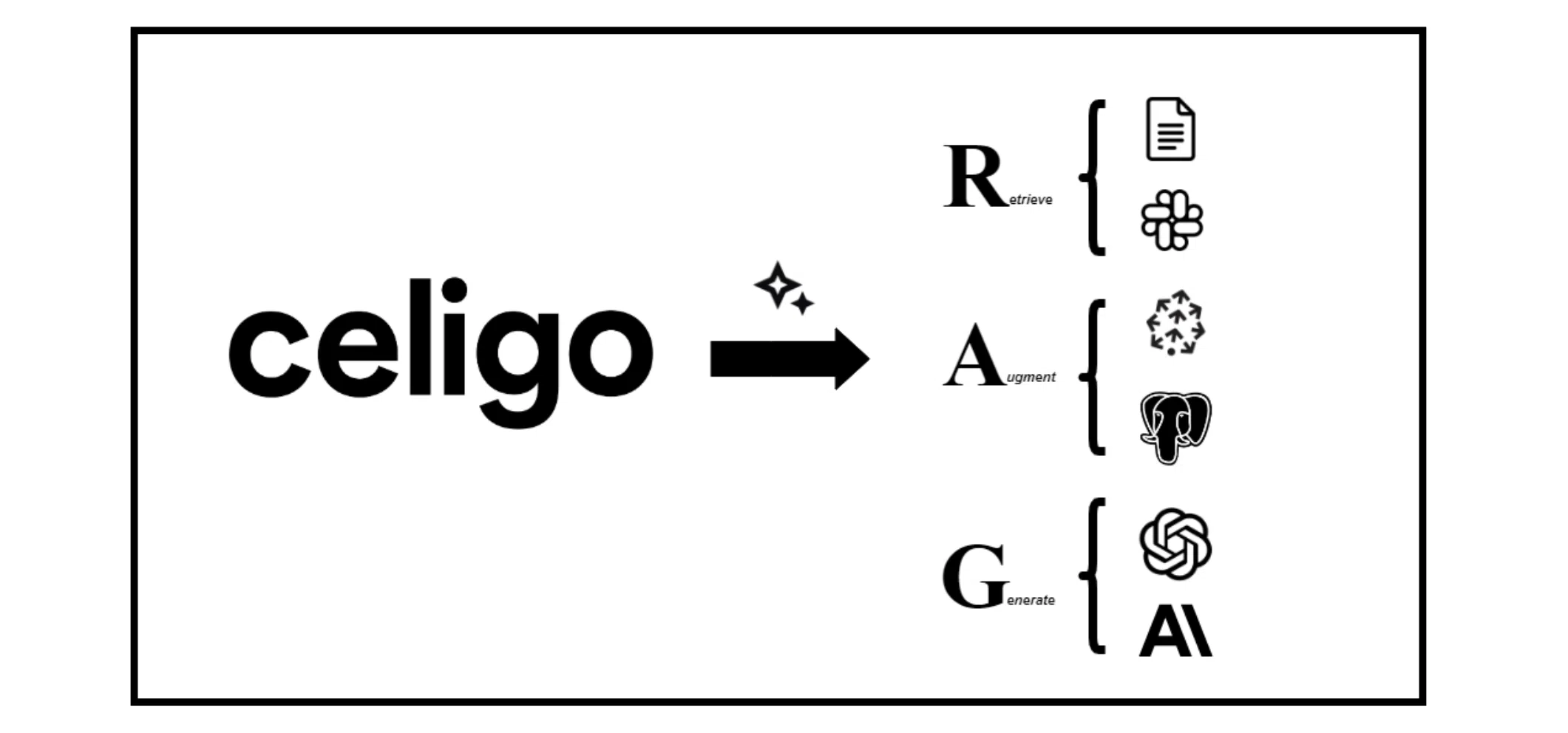
In summary, RAG works through three key steps:
- Retrieve Context (you retrieve specific relevant context)
- Augment Prompt (you augment your question with that data)
- Generate Answer (you generate an answer).
Now, the real trick is figuring out the best technique for this precise selection of context.
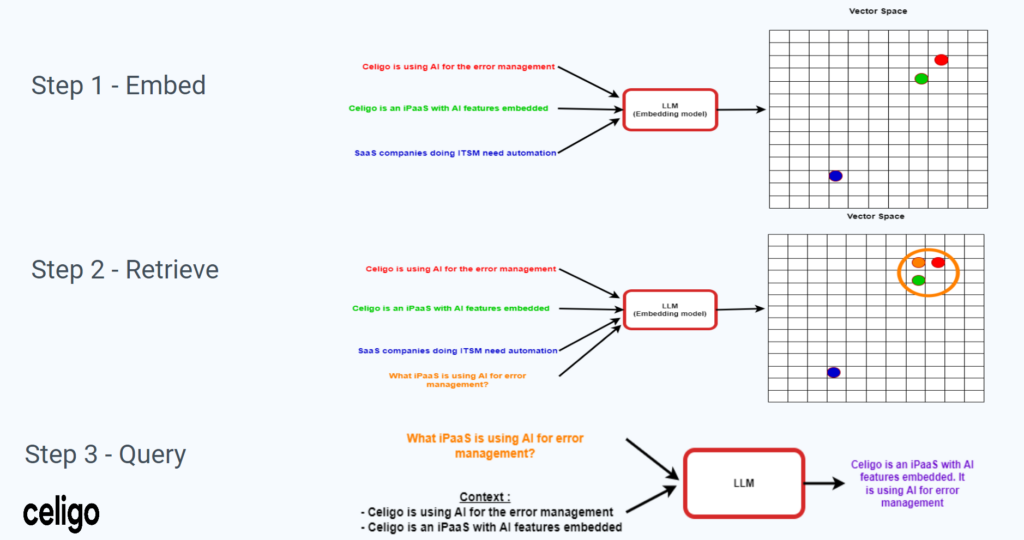
Vector embeddings and vector stores
Understanding Vector Embeddings
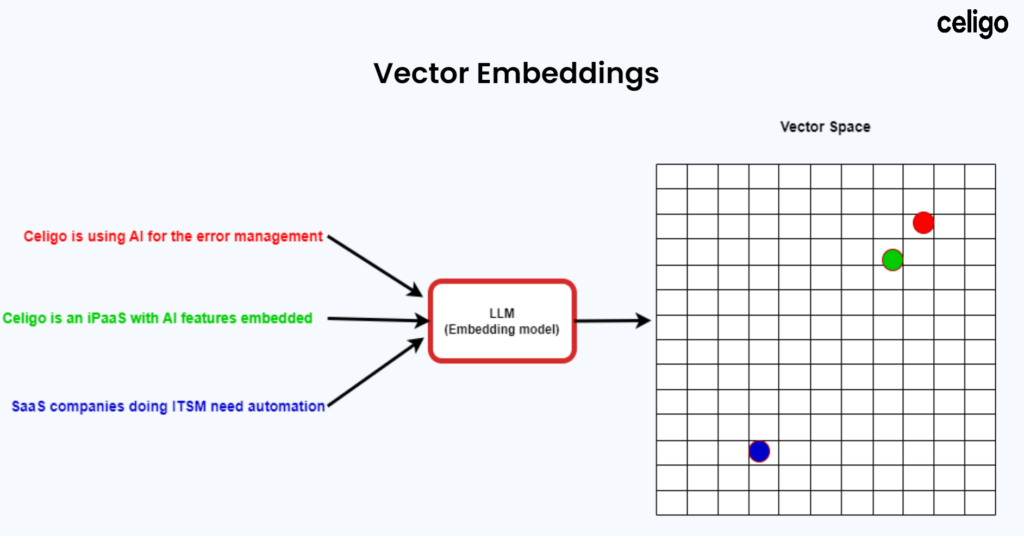
Vector embeddings convert words and documents into numerical representations (vectors) that can be processed by computers.

These vectors are placed in a multi-dimensional space where similar vectors are located near each other.
Vector stores
Vector stores are specialized databases designed to store and retrieve vectors efficiently. They allow users to find relevant information quickly by identifying vectors that are similar to a given query (similarity search).

Architecture of the RAG application

Steps to Implement RAG
- Loading data: Import data from various sources such as documents, databases, and emails.
- Indexing: Convert the data into vectors and index them in a vector store.
- Retrieving: Use the vector store to find relevant vectors based on a query.
- Augmenting: Add the retrieved information to the query.
- Generating: Use the augmented query to generate a response.
Practical Examples
At Celigo, we’ve built internally multiple Knowledge Bots that use RAG applications as the main engine:
AI Product Bot
This bot uses data from specific internal Slack channels and official documentation to answer questions about the product.
AI Support Bot
Provides support agents with semantic search capabilities based on accumulated knowledge from previous customer interactions to reduce the support team’s MTTR.

The Power of combining an iPaaS and AI
Integrating AI (especially RAG) with Integration Platform as a Service (iPaaS) platforms like Celigo can significantly enhance the creation and functionality of RAG applications.
Here’s how iPaaS platforms provide crucial support in this process:
Data integration
Celigo’s iPaaS excels at connecting various data sources, including databases, CRMs, ERPs, and cloud applications. This capability is essential for RAG applications, which must pull relevant data from multiple sources to provide accurate and context-rich responses.
Data transformation
Once the data is integrated, it must often be converted into specific formats required by different applications and AI models. Celigo handles this transformation seamlessly, ensuring that data is in the right format for processing and analysis.
Data orchestration
Managing the flow of data between different endpoints is critical. iPaaS platforms provide robust data orchestration capabilities, allowing you to define the sequence and logic of data transfers. This ensures that the right data is available at the right time for your RAG application.
API management
Effective communication with external APIs, such as those provided by OpenAI, is vital for RAG applications. iPaaS platforms facilitate this communication by offering comprehensive API management tools. This enables seamless integration with external services, enhancing the functionality of your AI applications.
Security
Security is a top priority when dealing with sensitive data. Celigo’s iPaaS offers Security by Design, as well as all tools like filters and embedded authentication and authorization mechanisms for APIs. These features ensure that data is protected and only accessible to authorized users and systems.
Error management
Handling errors and exceptions can be complex, but Celigo simplifies this process with built-in error management layers. These tools automatically manage errors and exceptions, making it easier to incorporate robust error handling into your workflows.
Unlimited connectivity with prebuilt integrations
Celigo’s iPaaS currently supports more than 400 connectors and adds dozens of new connectors every few weeks. Those connectors are critical to extracting data that will form our knowledge base and perform many other tasks.
Interact with users: Celigo supports many communication applications, such as Slack and Microsoft Teams, that can be used in a RAG application.
Embed data: To embed our data in the previous section, we need a model that can create those vectors for us. Celigo has connectors for the best LLMs offering embedding services, plus open-source models served through Hugging Face APIs.
Store embeddings: Embeddings can be stored in vector databases like Pinecone or using a database connector for PostgreSQL (pgvector).
Connect to LLMs: Celigo offers pre-built connectors for OpenAI and Anthropic, two giants in the LLM landscape.
Leveraging AI, RAG, and iPaaS
Integrating an Integration Platform as a Service (iPaaS) with AI, particularly through advanced techniques like Retrieval-Augmented Generation (RAG), represents a transformative approach to leveraging AI in business environments.
Advanced iPaaS platforms like Celigo enable AI applications to deliver precise, context-rich responses by seamlessly connecting, transforming, and orchestrating data from diverse sources. This integration addresses the limitations of large language models (LLMs) and enhances the overall functionality and reliability of AI systems.
Embracing the combined strengths of AI and iPaaS is essential for any organization aiming to stay competitive and innovate in the ever-evolving technological landscape.
Transform your AI strategy
Celigo’s advanced iPaaS opens the door of possibility, connecting all of your data, paving the way to deliver AI-powered solutions.