What is a data ingestion pipeline? A complete overview


A data ingestion pipeline is the automated framework that moves data from multiple data sources into systems where it can be stored, processed, and analyzed. As organizations generate and collect increasing volumes of information across applications, databases, and digital channels, a reliable pipeline is essential for ingesting data consistently and making it available for business use.
What is data ingestion?
Data ingestion is the process of collecting and importing data from one or more source systems into a destination environment for storage, processing, or analysis. In simple terms, data ingestion refers to how organizations gather information from various data sources and move it into platforms where it can be used effectively.
It is important to distinguish data ingestion from a complete data pipeline. Data ingestion is the first stage of the process, focused on bringing data into a target environment. The broader pipeline includes additional activities such as validation, transformation, orchestration, monitoring, and delivery to downstream systems.
A simple data ingestion example is an ecommerce company that exports order records from its storefront every night and loads them into a data warehouse for reporting. Another example might involve collecting customer interaction data from a CRM and storing it in a data lake for future analysis.
Because modern businesses rely on information spread across many systems, data ingestion often works alongside data integration initiatives that connect applications, databases, and cloud services into a unified architecture.
How a data ingestion pipeline works
A data ingestion pipeline is the set of automated processes that moves data from source systems to a destination in a repeatable and reliable manner. Rather than manually exporting and importing information, organizations use pipelines to automate the flow of data across environments.
Most pipelines follow a similar pattern: extract data from source systems, optionally transform or validate it, and load it into a target destination where it can be consumed by analytics platforms, operational applications, or machine learning systems.
Why data ingestion pipelines matter
Data pipelines matter because analytics, reporting, AI initiatives, and operational workflows depend on accurate and timely information. Even sophisticated systems cannot produce reliable outcomes if the underlying data is incomplete, delayed, or inconsistent.
Poor data ingestion practices can lead to stale dashboards, delayed reporting cycles, fragmented customer records, failed automations, and inaccurate forecasting. These issues affect both technical teams and business stakeholders.
Reliable data ingestion enables organizations to make faster decisions, improve visibility across operations, support real-time business processes, and build trust in the information used throughout the company.
Key stages of the pipeline
Connect to data sources: The process begins by identifying and connecting to relevant data sources, such as databases, SaaS applications, files, devices, or external APIs.
Extract the data: Data is extracted from the source system through queries, file transfers, APIs, change logs, or streaming data mechanisms.
Validate and transform: Pipelines often apply validation checks, cleansing rules, enrichment logic, or lightweight transformations to ensure the data meets downstream requirements.
Load into a destination: The processed data is loaded into a data warehouse, data lake, operational database, or another target environment. Analytical workloads commonly land in a warehouse, while raw and unstructured information often resides in a lake.
Types of data ingestion
Organizations typically select an ingestion approach based on how quickly data must become available and how much information needs to be processed. The most common approaches are batch processing, real-time ingestion, and micro-batching.
Batch processing
Batch ingestion collects and moves data at scheduled intervals, such as hourly, daily, or weekly. Instead of processing records immediately, the system accumulates information and transfers it as a group.
This approach works well for high-volume workloads that do not require instant updates, including financial reporting, periodic synchronization jobs, and data warehouse refreshes. Batch processing is generally easier to implement and more cost-effective than real-time alternatives.
Real-time ingestion
Real-time ingestion continuously moves data as it is generated, minimizing latency between creation and availability. Information flows through the pipeline almost immediately after events occur.
This approach is commonly used for fraud detection, operational monitoring, live dashboards, and customer personalization experiences. Real-time ingestion often relies on APIs, event-driven architectures, and streaming data platforms that can process information continuously.
Micro-batching
Micro-batching sits between traditional batch processing and full streaming architectures. Instead of processing data continuously, the system groups records into very small batches that are processed every few seconds or milliseconds.
This model can provide near-real-time performance while avoiding some of the operational complexity associated with large-scale streaming data systems. It is often attractive for teams that need fresh data without implementing a fully event-driven architecture.
Data ingestion vs. ETL and ELT
Data ingestion, ETL, and ELT are closely related concepts, but they are not the same thing. Data ingestion refers specifically to moving data into a destination system, while ETL and ELT describe how transformations are handled during that movement process.
In ETL (extract, transform, load), data is transformed before being loaded into the destination.
In ELT (extract, load, transform), raw data is loaded first and transformed afterward within the destination environment, often a cloud data warehouse.
As cloud platforms have become more powerful and scalable, ELT has grown in popularity because organizations can perform transformations directly within the warehouse. Regardless of the approach, ETL and ELT frequently operate as components within a broader data pipeline and data integration strategy.
Common data ingestion challenges
Building and scaling data ingestion capabilities often introduces operational and architectural challenges.
- Data quality issues: Data quality problems can emerge when source systems contain duplicate, incomplete, inconsistent, or inaccurate records. Poor-quality data reduces trust in reporting and analytics.
- Schema drift: Source applications may change field names, structures, or formats without warning. These changes can break ingestion processes and create downstream errors.
- High-volume and high-velocity workloads: Processing large datasets or streaming data at scale can strain infrastructure and increase the risk of performance bottlenecks.
- Latency mismatches: Different business processes have different timing requirements. A pipeline designed for daily reporting may not support use cases that require near-real-time updates.
- Security and compliance requirements: Organizations frequently move sensitive customer, financial, or operational information between systems. Security controls and regulatory requirements must be considered throughout the ingestion process.
- API limits and source constraints: Many cloud applications impose API rate limits or data access restrictions that can affect throughput and reliability.
Data ingestion pipeline design best practices
Effective data ingestion pipeline design focuses on creating reliable, scalable, and maintainable architectures that can evolve alongside business needs.
Choose the right ingestion model
Batch, real-time, and micro-batch approaches each serve different requirements. The appropriate model should align with business latency expectations, source-system capabilities, downstream consumption patterns, and operational constraints.
Establish data quality and schema governance
Strong governance practices help ensure that data quality remains consistent as systems grow. Validation rules, schema management, deduplication processes, and ongoing monitoring reduce the risk of poor-quality data entering downstream environments.
Design for scalability and observability
As data volumes increase, pipelines should support monitoring, alerting, retry mechanisms, and error handling. Observability allows teams to identify issues quickly and maintain reliable performance as workloads expand.
Start with business-critical data sources
Organizations often achieve the greatest value by prioritizing high-impact data sources first, including ERP systems, CRM platforms, ecommerce applications, and financial systems. Once foundational integrations are stable, additional sources can be incorporated into the broader data pipeline architecture.
Data ingestion pipeline tools
The right tooling depends on the type of data being processed, the scale of operations, existing technology investments, and the complexity of integration requirements.
Open-source ingestion tools
Open-source ingestion tools provide freely available source code that organizations can customize and self-host. They are often well suited for engineering-focused teams that require flexibility, deep customization, and control over infrastructure while minimizing licensing costs.
Cloud-native ingestion services
Cloud-native ingestion services are managed offerings provided by cloud vendors. These platforms handle ingestion, orchestration, and transformation within a specific cloud ecosystem, making them attractive to teams that want to reduce infrastructure management and operate primarily within one cloud environment.
Managed connector platforms
Managed connector platforms provide prebuilt connectors that move data between databases, SaaS applications, and analytical destinations with minimal configuration. They are often used by organizations seeking reliable, low-maintenance pipelines without extensive custom development.
iPaaS and integration platforms
Integration Platform as a Service (iPaaS) solutions focus on application-to-application connectivity, workflow automation, and operational data movement. Rather than targeting large-scale analytical ingestion workloads, they help organizations move and synchronize business data across operational systems.
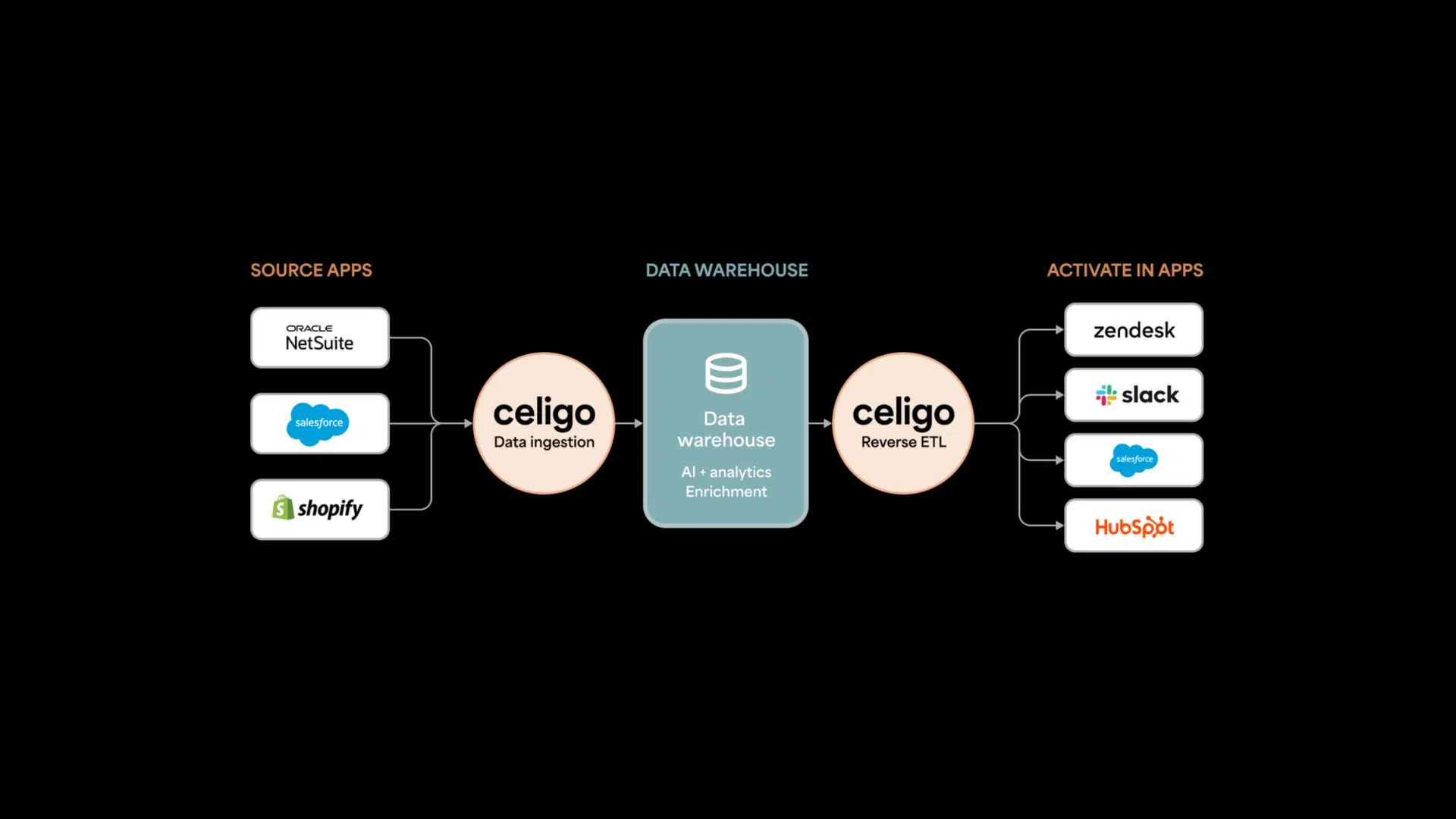
Celigo is an example of an iPaaS platform. It connects source applications such as ERP systems, CRMs, ecommerce platforms, and other business applications to destination systems, serving as an orchestration layer for operational data ingestion and business process automation.
How Celigo supports your data ingestion pipeline
Modern data architectures often include multiple tools, each serving a distinct purpose. While some platforms specialize in loading analytical data into warehouses and lakes, Celigo focuses on operational data movement across enterprise systems.
Celigo acts as an integration and orchestration layer that connects SaaS applications, ERP platforms, ecommerce systems, CRMs, databases, and other business-critical data sources. This enables organizations to move and synchronize data reliably between operational systems and downstream destinations.
The platform supports prebuilt connectors and API-based integrations for common business applications, helping teams reduce development effort while accelerating deployment. It also provides data transformation and mapping capabilities that allow information to be standardized as it moves between systems.
In addition, Celigo includes workflow orchestration, monitoring, and error-handling capabilities that help organizations maintain reliable data flows at scale. These capabilities are particularly valuable in environments where business operations depend on consistent information exchange across multiple applications.
For organizations moving operational data across ERP, ecommerce, CRM, and SaaS environments, Celigo provides the governed data integration layer that helps make data ingestion scalable, reliable, and manageable.
Get a demo to learn how Celigo can support operational data movement and enterprise-wide integration initiatives.