Context engineering: Best practices for data integration
 Updated Nov 19, 2025
Updated Nov 19, 2025


Context engineering is the process of designing and delivering the exact information an AI system needs, at the right moment, in the right structure, and from the right source, to produce accurate, grounded, and auditable results. It treats context as something you build intentionally, gathering data from trusted systems, cleaning and shaping it, breaking it into usable parts, and enriching it with extra details.
The goal is to feed the model well-prepared, relevant context along with clear instructions so its output is accurate and reliable.
Here, we’ll discuss context engineering, the need for data integration, and the principles, design patterns, and architectural strategies used to deliver structured, high-quality context to AI systems.
Context engineering vs. prompt engineering
Prompt engineering focuses on how you ask a model to act; context engineering emphasizes what the model sees, how it sees it, and when that context is made available.
The goal is not just to achieve better responses, but to produce predictably useful outputs that reflect the most current, well-governed, and verifiable information available.
It is about connecting the right systems, retrieving and ranking the right information, formatting it into model-ready structures such as JSON or XML, and orchestrating that data at the right time. The result is an AI that produces grounded, current, and auditable answers rather than guesses.
Why prompt engineering isn’t enough
Prompt engineering is useful for shaping how an AI model behaves, through tone, instruction design, or response formatting. But prompt design alone can’t compensate for missing, outdated, or poorly structured data. When models hallucinate, return stale information, or miss critical details, the root cause is often a lack of well-delivered context, not a weak prompt.
Context engineering fills that gap. It handles the hard problems of enterprise AI: connecting to the right systems, retrieving relevant data, shaping it into model-ready formats like JSON or XML, and delivering it at exactly the right point in the workflow. Where prompt engineering is declarative, context engineering is architectural.
It ensures the model operates on facts, not guesswork, and that the facts are current, governed, and aligned to business logic.
Where enterprise context comes from
In enterprise environments, the data that forms useful context often spans multiple systems — ERPs, CRMs, data warehouses, internal wikis, product catalogs, ticketing platforms, chat threads, and more.
The challenge is to bring all those systems together into a single, repeatable pipeline that not only consolidates data but continuously delivers the right context to your AI systems at the right time.
This means ensuring the model has access to your most current product information, policy updates, customer interactions, and internal knowledge, all in a format it can use. Without this alignment, even the most capable models risk generating inaccurate, outdated, or non-compliant responses. Context engineering solves this by creating a dependable flow of structured, governed data that evolves alongside your business.
Meeting these challenges doesn’t require a patchwork of scripts. With the right integration architecture, context engineering can be standardized, governed, and scaled with confidence.
Challenges in delivering context at scale
Most enterprises already have the data their AI systems need—but it’s fragmented, inconsistent, or locked inside systems that don’t talk to each other.
Delivering context at scale means solving for multiple constraints at once:
- Freshness: Data must reflect the current state of the business (policies, inventory, and customer activity) not last week’s exports.
- Structure: Context must be formatted for models to use without confusion or hallucination. That often means normalized schemas, redacted fields, and compact payloads.
- Governance: Sensitive data must be filtered, masked, or excluded entirely based on region, role, or compliance rules.
- Timing: Context needs to arrive precisely when it’s needed—triggered by business events or batched into just-in-time flows.
Context engineering addresses these challenges by standardizing how data is retrieved, transformed, and delivered into AI workflows.
With the right integration architecture, this process can be automated, auditable, and resilient, without relying on patchwork scripts or manual workarounds.
Context engineering principles
Core principles
Effective context engineering isn’t just about connecting systems; it’s about designing context with precision.
These core principles help ensure that what you deliver to the model is not only accurate but also aligned with the task at hand and resistant to failure.
State the goal first
Begin with a clear, one-line objective that defines what success looks like. This anchors the context to a specific outcome and improves consistency across flows.
Example: “Return a deduped CSV of Shopify orders ready for NetSuite import.” This keeps every step aligned and makes the review straightforward.
Constrain everything
Specify what inputs are allowed, which systems or APIs can be used, what formats are acceptable, and what to avoid. Constraints reduce ambiguity and prevent costly errors.
Show, not tell
Provide one or two short, realistic examples that match your domain. Good examples teach format, tone, and level of detail faster than long explanations
Ground in facts
Prefer retrieved documents, record IDs, and references to source systems over memory. Include citations or source identifiers when possible so results can be verified.
Make evaluation explicit
Define acceptance criteria up front. Add a quick self-check list so the workflow can confirm completeness before returning a result.
Together, these principles form the foundation of repeatable, auditable, and high-integrity context workflows, especially in production settings where accuracy and compliance matter.
How to structure model-ready context
Structure your context in order of importance.
| Component | Purpose |
|---|---|
| System and policy | Define role, boundaries, and any compliance or governance rules. Keep this unambiguous so downstream steps cannot miss or override these constraints. |
| Task brief | State the objective and success criteria in 2–5 bullets. Clearly describe what a good result looks like and what should be excluded. |
| I/O contracts | List required inputs, available tools or APIs, and expected output schema. Include minimal schemas (JSON, CSV, etc.) with field types and formatting rules. |
| Examples | Include 1–2 privacy-safe, domain-specific examples. Optionally add a negative example with a brief note on what’s incorrect or noncompliant. |
| Edge cases and don’ts | Call out known failure modes—e.g., how to handle missing data, rate limits, PII exposure, or deduplication logic. |
| Self-check | Define a short checklist for completeness. Example: “All rows include order_id, currency is normalized, duplicates removed by order_id and email.” |
Prompt patterns that work
This section covers specific prompt formats and techniques that improve consistency when using AI in structured workflows.
| Pattern | Description |
|---|---|
| Role and objective | Start with a clear role and goal. Example: “You are an integration QA assistant. Your goal is to verify that today’s order export meets the schema and dedupe rules.” |
| Tight examples | Use small, realistic snippets that mirror your real formats. One good example per output type is often enough. |
| Contrastive example | Show a subtle, common mistake alongside a corrected version. Helps the model learn what to avoid and how to fix it. |
| Chain of verification | Request a brief checklist, diff, or validation summary rather than internal reasoning. This keeps outputs concise and auditable. |
| Reinforce critical instructions | Place the most important instruction at the top, and repeat a short summary of it right before the final “You will now …” step. This improves adherence in longer contexts and reduces conflicts. |
How Celigo’s iPaaS enables context engineering
Connectivity without code
Celigo offers a wide range of prebuilt connectors and universal adapters such as HTTP, JDBC, SFTP, GraphQL, and webhooks. This makes it easy to pull in customer records, product catalogs, policies, tickets, specifications, and FAQs, and then send answers or citations back to the tools people already use, such as Slack, email, or case management systems.
Event listeners can react to business changes and trigger targeted updates to keep the knowledge your AI relies on accurate and current.
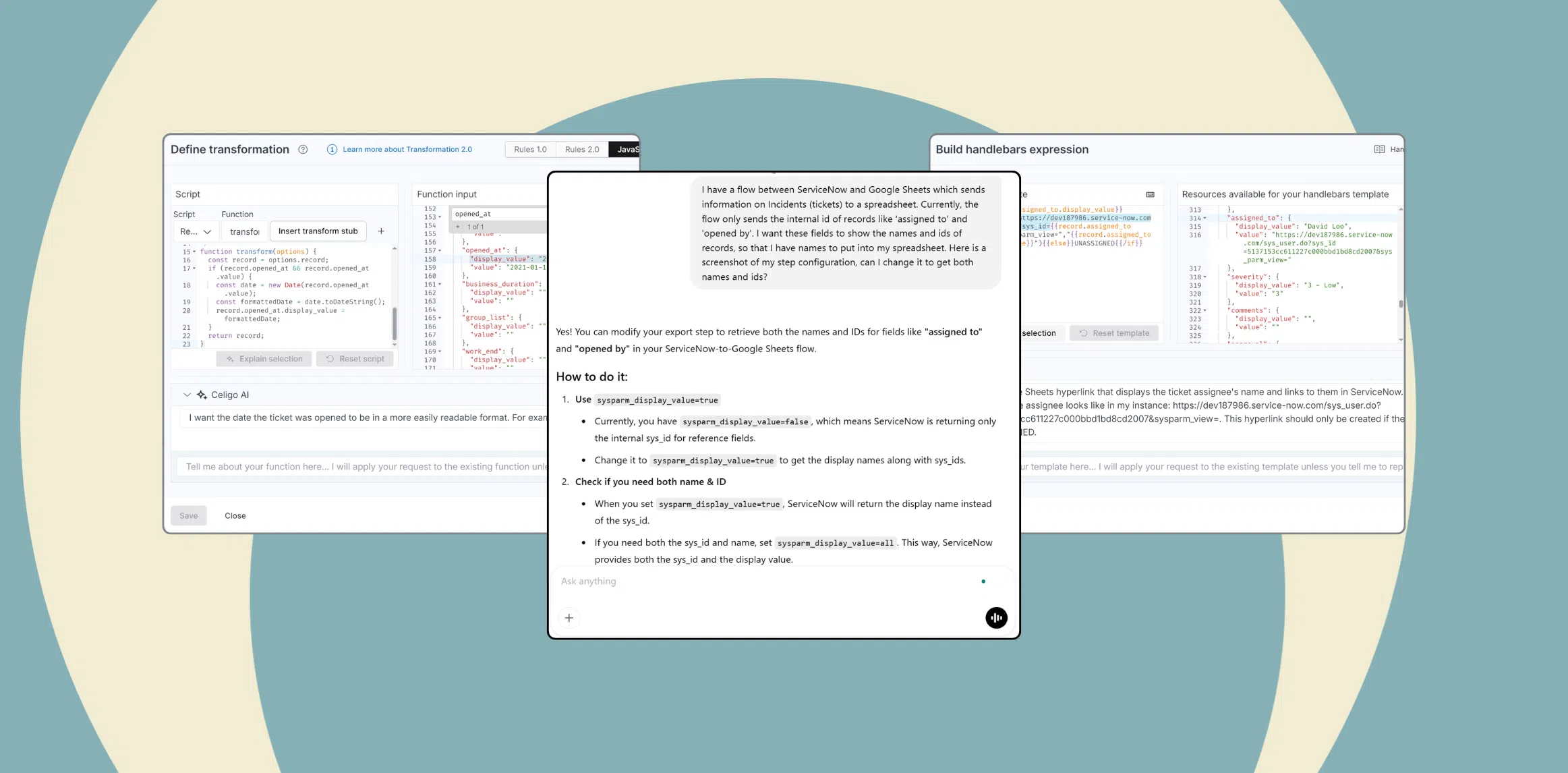
Transformation for model-ready payloads
Using Flow Builder and transformation steps, Celigo helps clean and normalize records, map schemas, remove duplicates, and enrich content. You can break long documents into smaller chunks, add metadata such as source, owner, timestamps, and permissions, and shape the data into RAG-friendly structures like compact JSON or XML blocks with citation IDs.
Built-in policy filters such as PII redaction, field masking, and data residency rules ensure that only compliant data reaches the model.
![]()
Orchestration for just-in-time delivery
Flow scheduling, event triggers, branching make sure that the right context is delivered exactly when needed. Common patterns include nightly flows to refresh key resources, on-event updates using webhooks when policies change, and parallel retrieval from multiple systems merged and deduplicated through Celigo’s flow logic.
You can also pre-load key data ahead of peak hours using Celigo’s Lookup Cache, and rely on built-in retries, fallback routes, and escalation options to maintain reliability even when services are slow or temporarily unavailable.
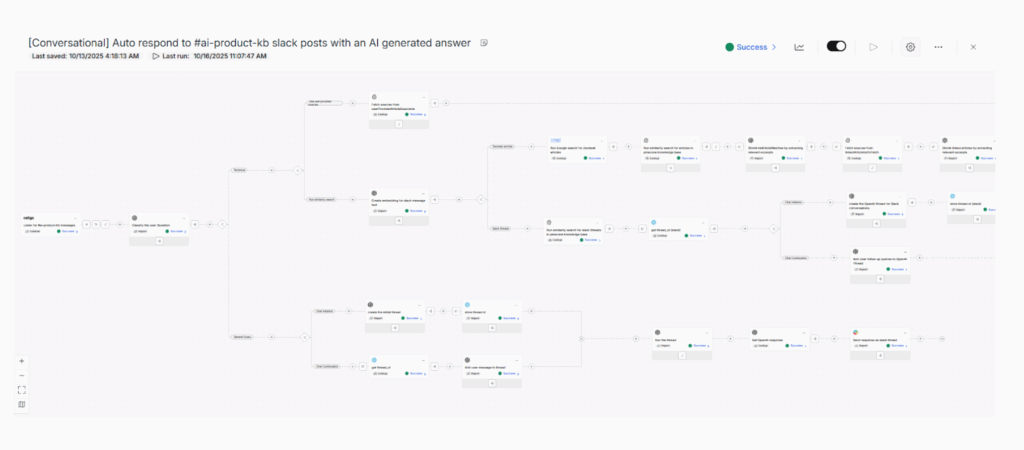
Governed integrations with external AI and data services
Many context workflows depend on external systems such as language model APIs, embedding generators, vector databases, or search and reranking services.
Within Celigo, all these interactions can be managed inside governed flows. Builders can use HTTP connectors or custom API integrations to standardize request and response formats, handle authentication and rate limits, and apply masking or quota rules when needed. Each call can be logged and traced using Flow trace IDs, making it simple to monitor, debug, and stay compliant.
Managing these interactions inside Celigo keeps your integrations unified and auditable instead of scattered across scripts and separate tools.
Security, governance, and resilience baked in
Celigo supports separate environments for development, testing, and production, as well as role-based access with SSO, encryption in transit and at rest, secure secret management, and detailed audit logs.
Operational features such as alerts, automatic retries, and dead-letter handling ensure that context pipelines recover gracefully from provider issues instead of interrupting user experiences.
Reference workflow and practical start
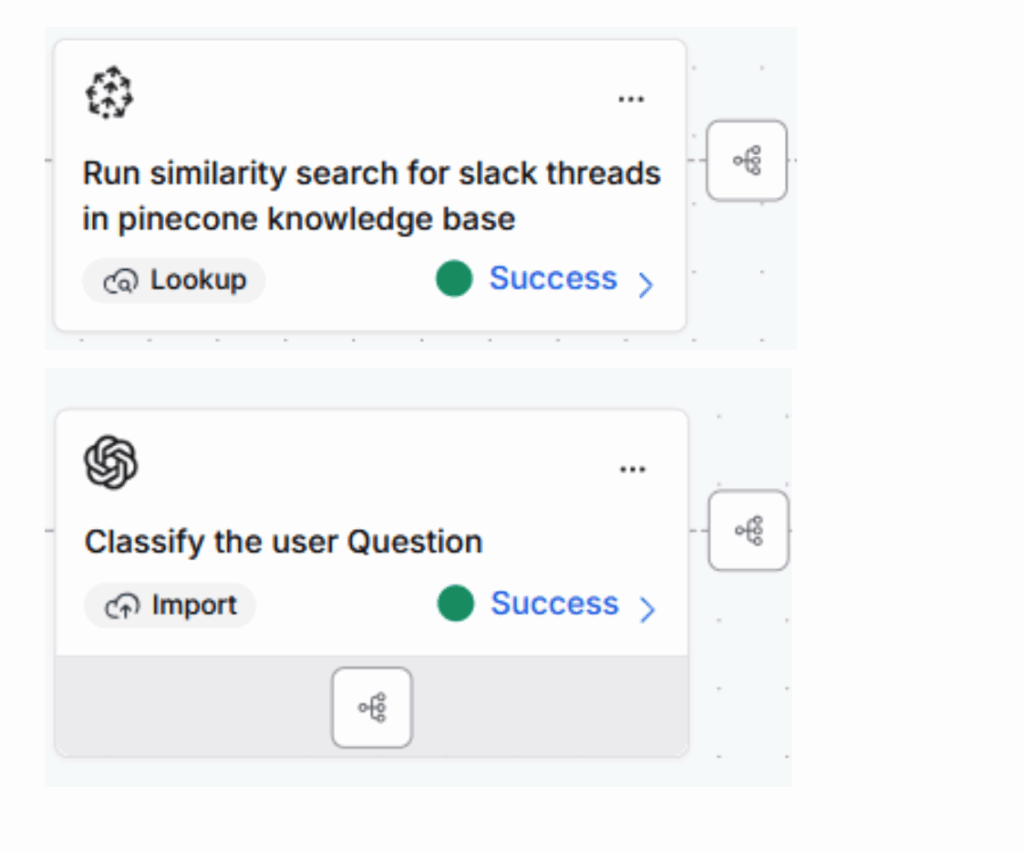
A simple practical pattern
- Ingest: Pull source-of-truth data and documents from business systems and storage.
- Transform: Clean, normalize, chunk, and tag with metadata and access controls.
- Embed and index: Create embeddings and write to your vector store or search index.
- Retrieve: For each request, fetch top-K relevant chunks with citations and timestamps.
- Assemble input: Wrap chunks in structured JSON or XML with instructions and constraints.
- Generate: Call your chosen model, capture outputs alongside citations and telemetry.
- Deliver and log: Post the result to the target channel, ticket, Slack, email, and persist traces for QA and analytics.
Context engineering in practice
Context engineering is the practical work that turns a capable model into a dependable workflow. If you have already built on Celigo, you have most of the plumbing you need, including connectivity, transformations, orchestration, API governance, and resilience, to ship context that is selective, structured, traceable, and timely.
For a deeper view of retrieval-augmented patterns, see Celigo’s RAG article. For additional perspective on effective context design, I will also point to Anthropic’s engineering article and use it as a companion resource to these principles.
Integration insights
Expand your knowledge on all things integration and automation. Discover expert guidance, tips, and best practices with these resources.