Biggest challenges in operationalizing AI and how to solve them


Many enterprises have already moved beyond AI experimentation. Pilots have been completed, models have been evaluated, and executive buy-in has been secured. But measurable business impact remains elusive.
The breakdown happens inside live CRM, ERP, billing, ecommerce, and operational systems. AI models can generate insights, predictions, and recommendations with impressive accuracy. But execution requires something most AI initiatives underestimate: reliable, governed connectivity to the systems that actually run the business.
The real challenge is architectural friction — the gap between what agentic AI systems decide and what enterprise applications can reliably execute. Operationalizing AI is fundamentally a systems engineering problem, not a model performance issue. When that gap isn’t closed, AI remains a reporting layer rather than an operational one.
This article examines the structural challenges that prevent agentic AI from functioning reliably in enterprise environments, and how to architect around them.
What Does “Operationalizing AI” Really Mean in Enterprise Environments?
“Operationalizing AI” is used broadly, but its meaning has precise implications in enterprise AI solutions deployed at scale. In this guide, we are defining true AI operationalization as:
- Embedding AI decisions directly into operational systems — CRM, ERP, billing, ecommerce, and support platforms — so that AI outputs drive real actions, not just recommendations.
- Enabling AI outputs to safely trigger, update, and orchestrate cross-system workflows — so a churn prediction doesn’t just generate an alert, but updates a CRM record, triggers a retention workflow, and notifies the right team.
- Ensuring AI-driven actions are governed, monitored, and auditable — so every AI-influenced decision has a traceable record, a responsible owner, and a recovery path.
- Preventing data drift and operational risk when AI interacts with multiple systems — because AI models trained on clean, unified data will behave unpredictably when deployed into fragmented, inconsistent environments.
At enterprise scale, operationalizing AI depends on whether enterprise systems can reliably execute AI-driven decisions. and whether the integration and automation foundation that governs reliable deployment (scalability under production load, model interpretability, infrastructure capacity) has been built ahead of AI deployment.
Operationalizing enterprise AI is fundamentally a problem of integration, orchestration, and governance.
What Are the Key Challenges in Operationalizing AI?
When AI pilots fail, there’s a structural cause. True operationalization demands robust integration, governance, and scalable infrastructure.
Explore each challenge below to diagnose potential pitfalls.
System-of-Record Conflicts and Data Inconsistency
Enterprise environments accumulate inconsistency over time. CRM, ERP, billing, and support systems are built and maintained independently, each with its own customer records, revenue definitions, and account hierarchies.
The result: duplicate customers, mismatched revenue figures, and conflicting entity definitions distributed across systems that were never designed to share a source of truth.
Imagine that a global logistics company deploys an AI model to identify upsell opportunities. The model is trained on clean, warehoused data. However, when it executes against the live CRM, it encounters three separate records for the same enterprise account, each owned by a different regional team.
The AI surfaces the same opportunity three times, triggers three outreach sequences, and a single customer receives duplicate communications from different sales reps within 48 hours. The failure isn’t the model, but the absence of a defined system of record.
AI amplifies inconsistency. When a model reads fragmented inputs, its outputs reflect those fragments. When it writes back — updating records, triggering workflows, adjusting pricing — it propagates the underlying conflicts rather than resolving them. Without standardized data pipelines and clear system-of-record ownership, AI decisions introduce operational instability rather than eliminating it.
Organizations that resolve entity conflicts before deploying AI report measurable reductions in exception rates and duplicate records. These improvements directly reduce manual reconciliation effort and improve downstream data quality.
This is the foundation on which any successful operationalization depends.
AI Outputs That Cannot Safely Execute Operational Actions
Generating an insight is not the same as acting on it. This is where many AI initiatives quietly fail — when there is no safe, governed path from decision to execution.
For example, imagine a subscription SaaS company deploys an AI model to detect billing anomalies and trigger corrective credits. The model identifies a valid overage charge. However, the integration between the AI system and the billing platform lacks scoped write permissions. A developer workaround gives the AI broad API access. During a routine model update, the AI misclassifies a legitimate charge, issues an unauthorized credit to 340 accounts, and there is no rollback mechanism. By the time the error is detected, the financial impact has already been posted.
This failure pattern is predictable. AI systems without scoped permissions, human-in-the-loop checkpoints for high-risk actions, and rollback mechanisms will eventually produce irreversible operational errors. The higher the autonomy, the higher the blast radius.
Action success rate — the percentage of AI-triggered operations that execute correctly without manual intervention — is the clearest indicator of whether AI is delivering operational value or operational risk. Organizations that implement scoped execution controls consistently see higher action success rates and lower mean time to recover (MTTR) from AI-triggered failures.
Integration Sprawl and Brittle Automation Layers
As enterprises layer AI onto existing workflows— and look to scale AI across business units — a predictable architectural pattern emerges.
These brittle automation layers make it difficult to scale:
- Point-to-point integrations built for specific model outputs
- Hard-coded scripts that break when outputs change
- Shadow automation tools deployed outside IT governance
- AI logic embedded directly inside application workflows — invisible to the teams responsible for maintaining them.
For example, a mid-market retailer builds an AI-powered inventory reordering system. The integration is written directly against the v2.3 ERP API. Six months later, the ERP vendor releases v3.0 with a restructured product hierarchy. The AI integration breaks silently — posting reorder requests to a deprecated endpoint that accepts calls but no longer triggers fulfillment. Inventory shortfalls accumulate for three weeks before the failure is diagnosed. There is no centralized monitoring layer to have caught it sooner.
AI increases integration complexity because its outputs are probabilistic, not deterministic. When model outputs shift — because data drifts, context changes, or a model is retrained — brittle integrations fail in ways that deterministic automation never did. Without a centralized orchestration layer, there is no single place to detect, diagnose, or recover from these failures.
Integration failures in AI workflows are measured in latency (decision-to-execution time), SLA adherence, and exception rate. Brittle architectures that require manual intervention to recover from AI-triggered failures directly increase MTTR and reduce the proportion of workflows that complete without human involvement.
Runtime Governance and Operational Control Gaps
Governance is treated too often as a compliance obligation rather than an operational one. In live AI deployments, the distinction is costly.
For example, a financial services firm deploys an AI model to flag high-risk loan applications and route them for expedited review. There is no audit log capturing which applications were flagged, on what basis, or what actions followed. A regulatory audit identifies a pattern of demographic disparity in routing outcomes. Because the AI system produced no traceable decision records, the firm cannot demonstrate whether the disparity was a model artifact, a data quality issue, or a workflow configuration error. The remediation process takes months and requires manual reconstruction of case histories.
Without runtime governance, enterprise AI operates in a visibility gap: no audit logs for AI-triggered changes, no alerting when AI-triggered API calls fail, no environment isolation between development and production, and no mechanism for tracing which workflows were influenced by AI decisions — or when. Model interpretability compounds this problem. When AI produces decisions that operational teams cannot explain or trace to specific inputs, accountability breaks down entirely.
Regulatory exposure is real and accelerating. Frameworks including the EU AI Act, GDPR, and CCPA impose explicit obligations around data privacy, transparency, explainability, bias monitoring, and human oversight for high-risk AI decisions. These are operational requirements that must be built into AI architecture before deployment — not retrofitted after an audit finding.
Governance gaps directly affect audit pass rates, remediation costs, and the time required to diagnose and recover from AI-triggered failures. Observable, auditable AI systems reduce MTTR, improve regulatory posture, and make it possible to detect model drift before it produces operational damage.
For teams building governance frameworks around AI workflows, this overview of enterprise integration governance covers the core architectural requirements.
Integration and System Connectivity Challenges
Beyond organizational and governance issues, many AI initiatives fail at the system architecture layer. Operationalizing AI requires reliable, real-time connectivity between AI models, agents, and core enterprise systems. At scale, this connectivity is one of the most underestimated failure points in enterprise AI deployment.
This section covers the infrastructure failure modes that governance and organizational alignment alone cannot solve. Without resilient integration infrastructure and standardized data pipelines, AI projects cannot move reliably from pilot to production.
Event-Driven Orchestration Gaps
AI operates on real-time signals. A churn prediction is most valuable at the moment risk is detected, not 24 hours later when a batch process delivers it. A pricing anomaly requires an immediate response, not an overnight sync.
Most enterprise integration architectures were designed for scheduled batch processing, not real-time event response. When AI systems are layered on top of batch-based integrations, the latency between decision and execution erodes the value of the AI entirely. A model that detects a fulfillment risk six hours after the triggering event is operationally equivalent to one that didn’t detect it at all.
Real-time AI execution requires event-driven orchestration: the ability to trigger downstream workflows the moment a model produces an actionable output. This is an architectural requirement that must be scoped into the integration design, not assumed from existing infrastructure.
API Inconsistency and Version Drift
AI systems depend on stable, well-defined APIs at every integration point. Every read from a CRM, every write to an ERP, and every trigger sent to a billing system are potential failure points when the underlying API changes without coordination.
In practice, enterprise systems evolve continuously. APIs are versioned, deprecated, and replaced on vendor schedules that AI integration teams often don’t control. When AI integrations are built against a specific API version and that version changes, the integration can break silently — accepting calls but producing incorrect results, as in the inventory example above.
Inconsistent API standards across systems compound the problem: different authentication schemes, data formats, pagination logic, and error responses mean that each integration must accommodate a different behavioral contract.
At scale, unmanaged API version drift directly increases operational risk and maintenance burden, and reduces the reliability of AI-driven actions across the enterprise.
Error Handling Limitations at Scale
Traditional integration patterns were designed for deterministic workflows: a defined input produces a defined output. AI introduces probabilistic variability that deterministic error handling was never built for.
When an AI-triggered action fails — because the model output was outside an expected range, a downstream system was temporarily unavailable, or an input was malformed — most legacy integration layers have no:
- Retry logic designed for probabilistic outcomes.
- Fallback to a deterministic rule.
- Escalation to human review.
The failure either propagates silently or halts the workflow entirely, compounded by a skills gap among integration teams trained on deterministic patterns rather than probabilistic AI workflows.
At enterprise scale, AI-driven workflows will regularly encounter edge cases that deterministic logic never anticipated. Retry logic, exception handling, and fallback routing must be redesigned specifically for AI workflows — not inherited from batch integration patterns built before probabilistic outputs were a consideration.
Scalability compounds every one of these barriers. A model that performs reliably under development load may degrade significantly when processing thousands of concurrent events across live systems. Computational resource constraints — including processing capacity, memory, and API throughput limits — directly affect whether AI can execute at the speed and volume that enterprise workflows require. These infrastructure requirements must be scoped during architecture design, not discovered during a production incident.
Without resilient integration infrastructure and standardized data pipelines, AI models and agents cannot operate reliably in production environments. The quality of the model is irrelevant if the surrounding infrastructure cannot handle the realities of live enterprise systems.
How Enterprise Teams Overcome AI Operationalization Challenges
The challenges above are solvable — but the solutions follow a specific sequence. Organizations that try to scale AI before resolving data, integration, and governance foundations consistently encounter the same failure modes described above.
The following playbook addresses them in the order that reduces risk most effectively.
Step 1: Establish System-of-Record Clarity Before AI Execution
Before any AI system reads from or writes to operational environments, resolve the foundational question: which system owns which data?
You can do that by:
- Defining data ownership explicitly across CRM, ERP, billing, and support systems.
- Standardizing entity schemas — ensure that a “customer,” “account,” and “revenue event” mean the same thing in every system.
- Assigning unique, consistent identifiers that prevent duplication across platforms.
- Establishing clear rules for where AI reads authoritative data and where AI-triggered updates are permitted to land.
This work exposes a common skills gap — data ownership and schema standardization require cross-functional coordination that most AI teams aren’t staffed for.
But organizations that complete it before deployment consistently report measurable outcomes: reduced duplicate record rates, lower exception volumes in AI-triggered workflows, and fewer manual reconciliation cycles across integrated systems.
Without it, every AI initiative that touches operational systems inherits — and amplifies — the inconsistencies already embedded in those systems.
Step 2: Centralize Orchestration Instead of Embedding Logic in AI Models
Most AI projects embed workflow logic directly inside the model, which makes orchestration invisible, brittle, and hard to govern.
Models make decisions. They should not sequence the operational steps that follow. Workflow orchestration — the logic that determines what happens after an AI decision is made — belongs in a dedicated orchestration layer, separate from the model itself.
This separation has direct operational benefits.
- Orchestration logic can be updated, versioned, and governed independently of the model.
- Integration assets become reusable across AI initiatives rather than being rebuilt from scratch each time.
- Business rules remain explicit and auditable rather than buried inside model behavior.
- When a model is retrained or replaced, the surrounding workflow doesn’t need to be rebuilt with it.
Centralized orchestration also enables the most reliable pattern for enterprise AI at scale: combining AI decision-making with deterministic rule execution and human review checkpoints in deliberate proportion. Not every workflow step requires AI. Many steps are better handled by rules that are well-understood, low-risk, and consistent.
The organizations that operationalize AI most reliably are those that use AI where it adds the most value, and use deterministic logic everywhere else.
Step 3: Introduce Governance and Observability Before Scaling
Governance cannot be retrofitted after an AI system is in production. By that point, AI-triggered actions have already occurred without audit trails, API permissions are already broader than they should be, and the boundary between development and production is already blurred.
Build governance into the architecture before scaling:
- Role-based access controls and scoped API permissions for AI agents, so no model can write to systems outside its defined scope
- Audit logs for every AI-triggered system change — not for compliance alone, but for operational debugging and accountability
- Monitoring dashboards and alerting so that failures surface immediately, rather than accumulating silently
- Environment isolation between development, test, and production AI workflows to prevent misconfiguration from propagating into live systems
- Human-in-the-loop checkpoints for sensitive workflows — refunds, contract modifications, account changes — where the cost of an incorrect AI action exceeds the cost of a brief human review
- Organizations that implement these controls before scaling their AI solutions consistently see lower MTTR when AI-triggered failures occur, higher audit pass rates, and faster remediation cycles when model drift is detected in production.
Step 4: Design for Controlled Automation, Not Full Autonomy
Full autonomy is not the goal of enterprise AI operationalization. Reliable, governed, measurable automation is.
The most robust enterprise AI architectures define explicit thresholds — based on action type, risk level, and reversibility — that determine when AI executes autonomously and when human review is required. Routine, low-risk, easily reversible actions are strong candidates for full automation. High-stakes or irreversible actions benefit from a review step before execution.
Maintaining consistent governance across all automation types — AI-driven, rule-driven, and human-reviewed — ensures that audit trails are clean, failure modes are predictable, and operational teams can diagnose issues regardless of which component made a given decision.
Organizations that address data, integration, governance, and alignment in this sequence are substantially more likely to operationalize AI successfully and achieve measurable ROI. Critically, the infrastructure built for the first AI initiative becomes the reusable foundation for the next — compressing the time and cost of each subsequent deployment.
How Integration-First Platforms Reduce AI Operational Risk
Successfully operationalizing AI requires a production-grade infrastructure layer that can support the full operational demands of enterprise AI deployment.
Closing the gap between AI decision-making and reliable enterprise execution requires seven interconnected infrastructure capabilities:
- Event-driven orchestration: Real-time AI execution without batch-processing latency
- Cross-system workflow execution: Reliable connectivity between AI models and CRM, ERP, ecommerce, and finance systems at scale
- Centralized monitoring and retry logic: Detecting failures, surfacing errors, and recovering automatically from transient issues before they propagate
- Scoped AI agent access: Enforcing permissions at the API level so AI systems cannot operate beyond their defined boundaries
- Standardized data pipelines: Ensuring AI reads from and writes to authoritative, consistent data sources
- Environment isolation: Separating development, testing, and production AI workflows
- Governance and audit controls: Making every AI-triggered action traceable, reviewable, and recoverable
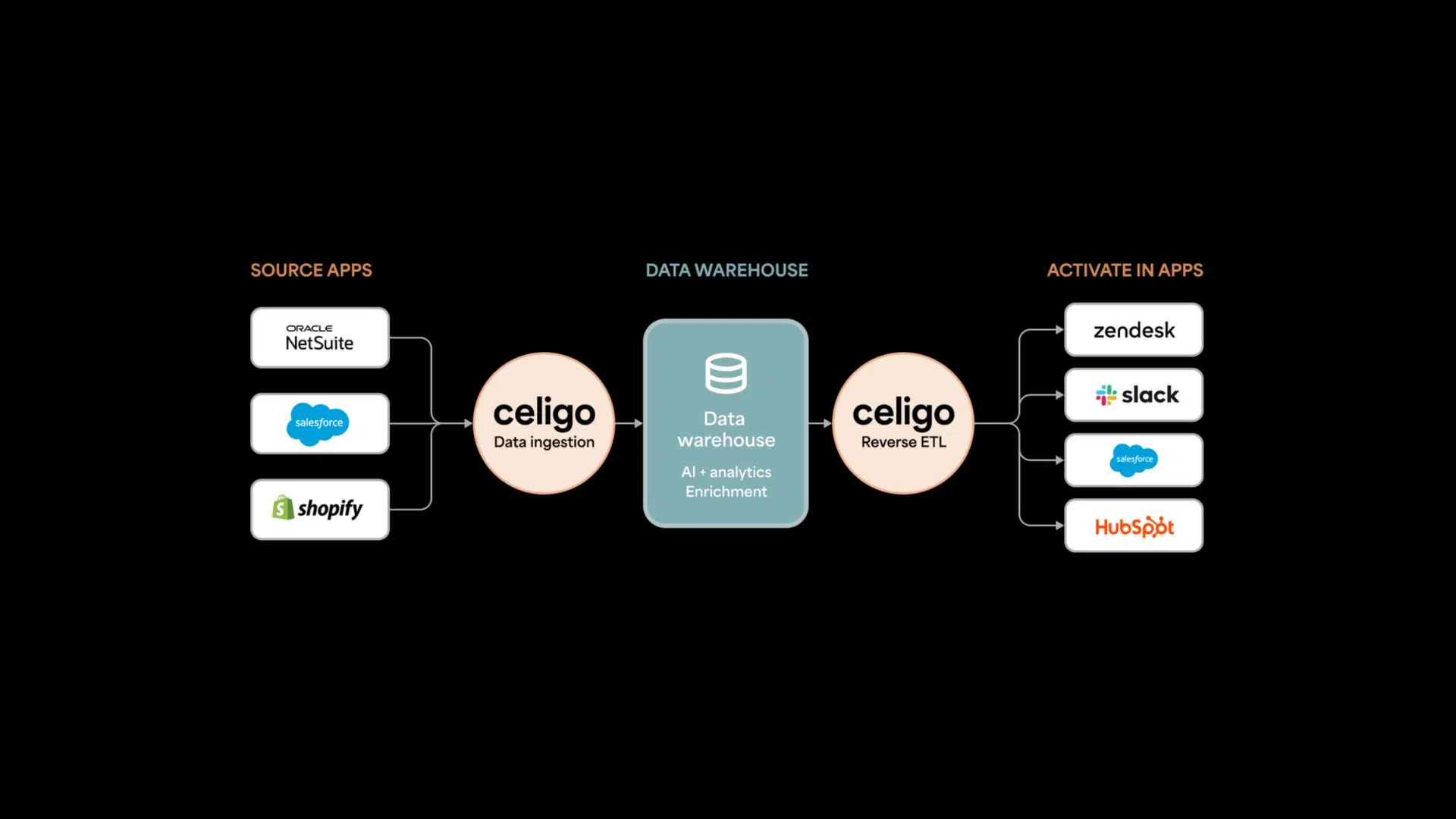
Celigo provides the orchestration and governance layer that enables AI systems to operate reliably across CRM, ERP, ecommerce, and finance systems. By standardizing data flows, managing API access, centralizing workflow monitoring, and providing retry and alerting infrastructure, Celigo allows enterprises to operationalize AI without rebuilding integration architecture for every new initiative. The result is an integration layer that scales with AI complexity — rather than breaking under it.
Ready to build a more resilient AI architecture?
→ Watch our 6 Automation Challenges Shaping 2026 webinar to see how enterprise teams are designing integration infrastructure that supports reliable, governed AI at scale.