AI initiatives won’t fix your broken processes. They will expose them.
 Updated Feb 25, 2026
Updated Feb 25, 2026

After hosting Celigo’s recent webinar on AI operationalization, one point became clear. AI does not transform operations by itself. It amplifies the systems already in place.
In well-designed environments, it accelerates performance. In fragmented ones, it accelerates friction.
Data readiness is contextual, not absolute.
One key takeaway was that waiting for perfect data is a mistake. No enterprise has complete and connected data across every system. If perfect data is the entry requirement, most AI initiatives will never move beyond planning.
But lowering the bar isn’t the answer, either.
A more practical approach is to narrow the scope to what you need to make informed decisions.
- What specific decision are we trying to improve
- Which data inputs directly influence that decision?
If the goal is more accurate cash flow forecasting, then accounts receivable, payables, and billing schedules matter. Marketing attribution tables probably do not. Data readiness should be defined relative to the use case, not a company-wide standard.
This reframes AI as a focused operational tool, not a sweeping transformation strategy.
Siloed AI cannot produce system-level insight
Another theme that surfaced repeatedly is architectural fragmentation.
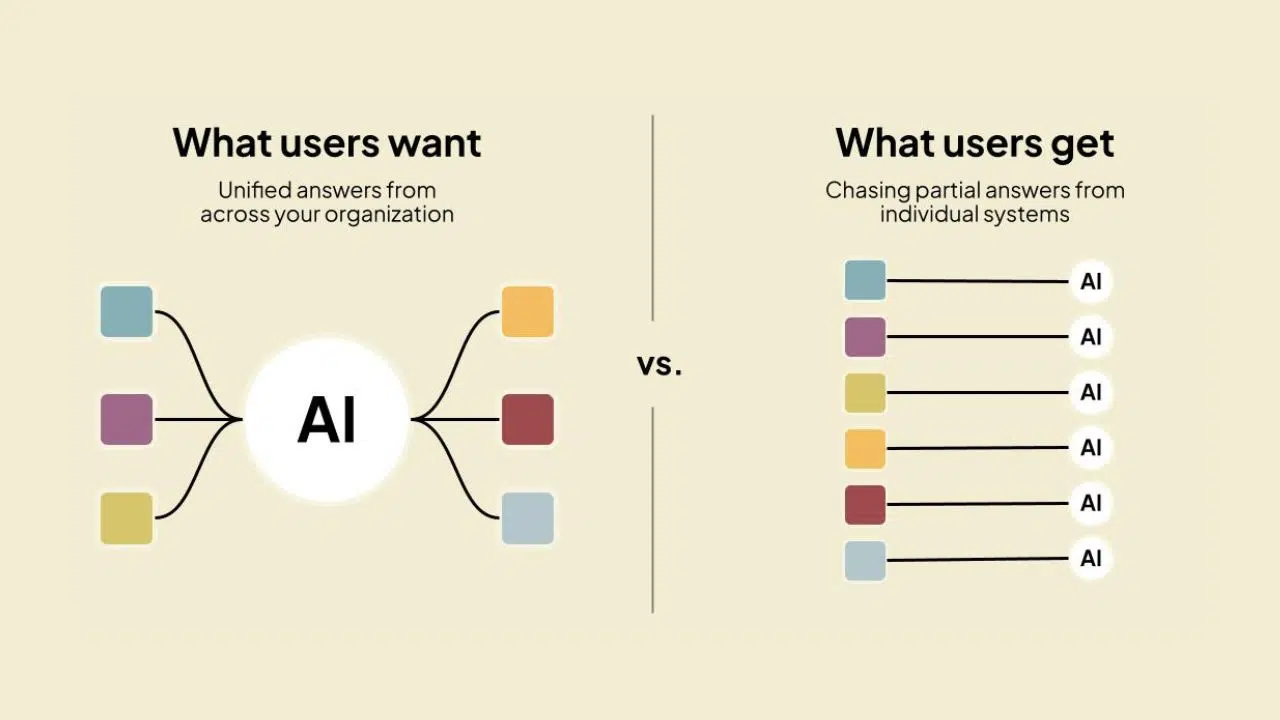
Most enterprises now have AI features embedded inside individual SaaS platforms. CRM systems have predictive scoring. ERPs surface anomaly detection. Finance platforms offer forecasting assistance. Each operates within its own boundary.
In practice, the decisions that drive performance span multiple systems.
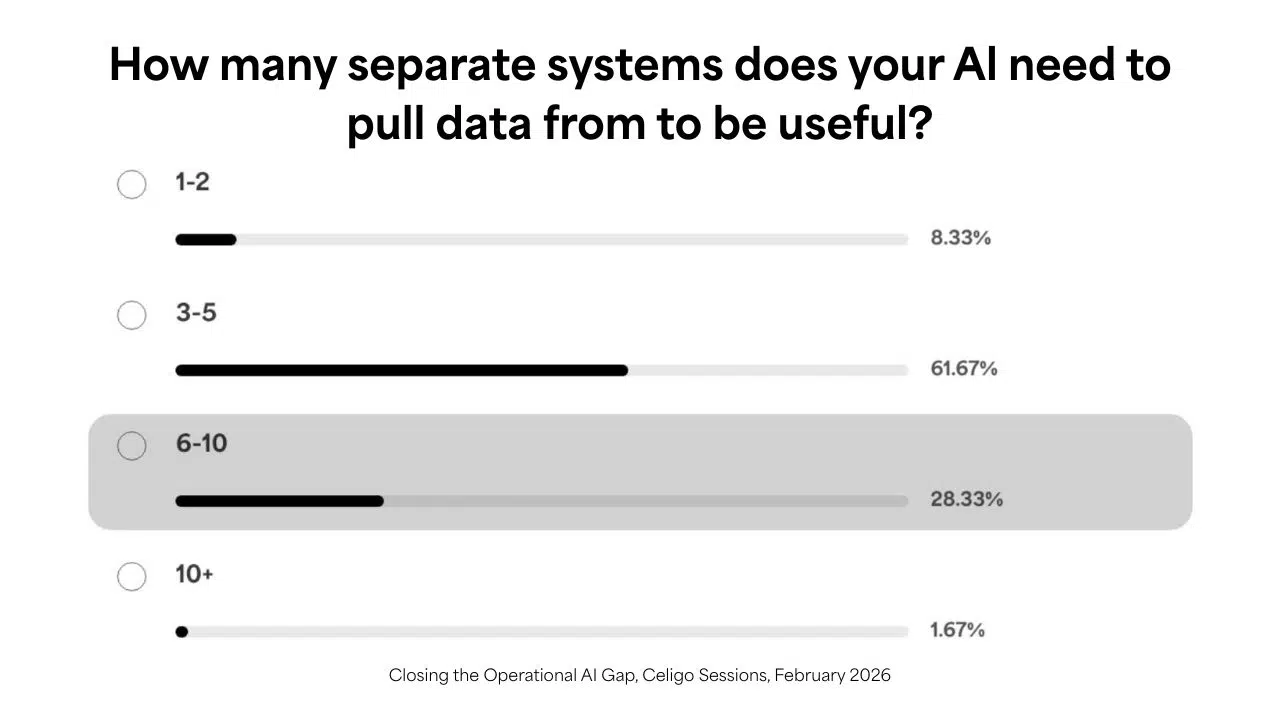
During the webinar, most attendees said their AI use cases depend on data from three to five systems, with many requiring even more. We saw that same pattern at last year’s AI Summit. Effective AI draws from multiple sources because the decisions it supports don’t respect departmental boundaries.
When AI operates on siloed data, it can only optimize within that silo. It may improve a local metric while degrading the broader workflow.
That’s why connectivity is foundational, not optional. Whether through an integration platform, a well-designed data layer, or disciplined API strategy, AI needs shared context. Without it, you’re adding intelligence to fragmented systems rather than improving the system itself.
The principle of least agency
There is also a tendency to over-apply AI.
One framework that resonated during the discussion was the principle of least agency. If a deterministic workflow can solve the problem reliably, it should. Deterministic automation is typically faster, cheaper, and more predictable.
AI systems, particularly generative models, introduce probabilistic behavior. That can be valuable when tasks require synthesis, pattern recognition across unstructured inputs, or judgment under ambiguity. It is unnecessary when the task is rule-based and stable.
Strategic restraint is often a stronger signal of maturity than aggressive deployment.
Shared ownership is a governance requirement
Operational AI initiatives often stall not because of technical limitations, but because of unclear accountability.
IT may own infrastructure, data pipelines, and security standards. Business teams own process design and performance outcomes. If those domains remain separate, AI initiatives become misaligned.
Effective implementations start with a shared definition of success. Which metric should move, which decision should improve, and what level of accuracy is acceptable?
Governance also cannot be an afterthought. Questions of access control, data privacy, audit trails, and explainability must be addressed early, especially in environments that handle regulated or sensitive information.
Enthusiasm for experimentation is understandable. But distributing agent-building tools broadly without corresponding governance structures introduces material risk.
Start with constrained, measurable use cases
AI efforts benefit from constraint.
Low-variance, repetitive processes with clear feedback loops provide a practical starting point. Early deployments should include human oversight, not as a permanent dependency, but as a calibration phase.
For example, Celigo uses AI to automatically read, categorize, and draft responses to common customer billing emails, turning a high-volume AR inbox into a manageable, consistent process.
Measurement of success should focus on business outcomes rather than activity metrics. Time saved and operational efficiency is often cited, but time alone does not indicate improved performance. More relevant indicators include error reduction, cycle time compression, forecast accuracy, cost containment, or business goals such as revenue impact.
Infrastructure choices should be evaluated for where you’re going, not just where you are.
Operationalizing AI starts from an enterprise integration platform
AI is not a shortcut around operational complexity.
Multipliers reward coherence and expose fragmentation.
Organizations that succeed will treat it as an extension of operational design, not a replacement for it. They will define specific outcomes, align ownership, and invest in connective architecture before scaling deployment.
During the webinar, I shared findings from research we ran with MIT Technology Review on what separates teams successfully scaling AI from those still stuck. The stat that keeps coming up: 90% of successful deployments rely on an integration platform.
If that gap sounds familiar, the on-demand recording goes deeper into the research and what leading teams are actually doing differently.


